背景
最近一个任务是做一个爬虫,而在这个框架构建过程中需要做到平滑水平扩展;因此,对于采集器而言,直接替换旧数据即可;而对于分析器而言,总不能重复解析相同数据,这会造成严重的性能浪费,特别是在此过程中需要使用OCR来分析图片。所以,想到将一致性hash算法应用到分布式数据处理中。
何为一致性hash算法
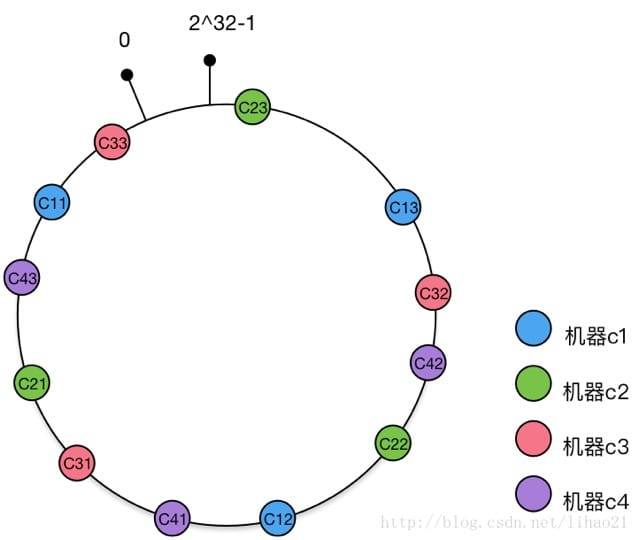
来源:在一致性hash算法之前,如果需要解决多个服务器内不同缓存的均匀分布,通过 m=hash(o)%n 这个公式作为基础进行;即在多个缓存服务器内,将不同的对象均匀的分散缓存到这些缓存服务器内;但是如果出现一台机器down掉或者增加了一条机器,那么根据之前的公式,几乎所有的缓存位置都将发生变化,造成缓存内容失效。
解决方案:不对服务器数量取模,而是对2^32次取模;2^32-1个点组成一个环,将服务器映射到这个环上的点;根据key hash后所处环上的点,按照顺时针获取最近的服务器节点,即将该内容缓存到这个服务器上。这就使得,即使有部分服务器节点down掉,down掉节点的缓存内容按照顺时针获取新的缓存服务器;即,并不是所有的缓存会失效。这就是相对于服务器数量取模的优点。
提升:上述的一致性hash算法仍旧存在一个问题,上述描述基于的一个前提是,各个服务器分布均匀。如果分布不均匀出现极端情况,那么就可能会出现大量甚至所有的内容都缓存到同一个服务器节点上,这种现象被称为hash环的偏斜。这时候,只需要将这些物理服务器节点复制多个分散到这个hash环上,那么就能够尽量减少这种偏斜的情况发生。如何复制?只要以物理节点为基础建立多个虚拟节点,这些虚拟节点指向物理服务器即可。
更为详细的一致性hash算法解说,可以查看这篇文章。
分布式数据处理思路
了解过一致性hash算法,可以看到本质上就是为了使得缓存内容均匀分不到不同的服务器,并且能够使得在增加或者删除服务器的时候,尽量减少对其他缓存内容的影响。而分布式数据处理,其实也可以使用这个思路。
- 构建一个以数据处理服务器映射出来的N多虚拟节点所在的一致性hash环
- 将对象key的hash计算,按照顺时针获取数据处理服务器
- 判断获取的数据处理服务器是否与当前的服务器一致,如果一致,则直接处理数据,否则忽略
实现
- 所有分析器应用注册到ZK注册中心
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| @Bean
public ZkLifeCycle zkLifeCycle() {
return new ZkLifeCycle();
}
public static class ZkLifeCycle implements ApplicationListener<ContextRefreshedEvent> {
@Override
public void onApplicationEvent(ContextRefreshedEvent event) {
ApplicationContext context = event.getApplicationContext();
ZkClient zkClient = context.getBean(ZkClient.class);
zkClient.register();
}
}
```
2. 每个分析器应用在启动的时候,通过ZK的客户端缓存分析器应用列表
```java
client.getConnectionStateListenable().addListener((curatorFramework, newState) -> {
if (ConnectionState.CONNECTED.equals(newState)
|| ConnectionState.RECONNECTED.equals(newState)) {
List<String> instances = getInstances();
instances.forEach(nodeHolder::addPhyNode);
}
});
|
- 监听ZK的节点变更事件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
PathChildrenCache watcher = new PathChildrenCache(client, rootPath, true, false, executorService);
watcher.getListenable().addListener((curatorFramework, pathChildrenCacheEvent) -> {
switch (pathChildrenCacheEvent.getType()) {
case CHILD_ADDED:
nodeHolder.addPhyNode(getNodePath(pathChildrenCacheEvent.getData().getPath()));
break;
case CHILD_REMOVED:
nodeHolder.delPhyNode(getNodePath(pathChildrenCacheEvent.getData().getPath()));
break;
default:
break;
}
});
try {
watcher.start();
} catch (Exception e) {
log.error("子节点状态监听器启动失败: {}", e.getMessage());
}
|
只有当其他客户端被删除或者增加的时候,才会触发节点持有容器的增加物理节点和删除物理节点操作。
- 获取对象key的hash值,根据hash值比较获取虚拟节点
1
2
3
4
5
6
| VirtualServerNode node = nodeHolder.getServerNode(houseId);
if (node != null && StringUtils.contains(node.getServerNode(), getCurrentServerName())) {
list.add(ziruHostingHouseMetadata);
}
|
节点持有容器的实现
在节点持有容器内,通过ArrayList数据结构来存储虚拟节点;并且持有一个Set集合,用来存储物理节点的节点名,防止出现重复添加的情况发生。同时,在增加物理节点的时候,会将该物理节点映射为5个虚拟节点,并以128bit的hash结果顺序排序。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
|
@Slf4j
public class VirtualServerNodeHolder {
private final static String VIRTUAL_SPLIT = "&&VN";
private final static int VIRTUAL_NUM = 5;
private final int seed;
private final Set<String> names;
private final List<VirtualServerNode> nodes;
public VirtualServerNodeHolder(int seed) {
this.seed = seed;
this.names = new HashSet<>();
this.nodes = new ArrayList<>();
}
public VirtualServerNodeHolder(int seed, List<VirtualServerNode> nodes) {
this.seed = seed;
this.names = nodes.stream().map(VirtualServerNode::getServerNode).collect(Collectors.toSet());
this.nodes = nodes;
}
public synchronized void addPhyNode(String serverName) {
if (serverName == null || nodes.isEmpty()) {
return;
}
if (names.contains(serverName)) {
log.error("已经存在相同名称节点 {},忽略该节点", serverName);
return;
}
names.add(serverName);
for (int i = 0; i < VIRTUAL_NUM; i++) {
String virtualServerNodeName = serverName + VIRTUAL_SPLIT + i;
MurmurHash3.HashValue hash = getHash(virtualServerNodeName);
VirtualServerNode vsNode = new VirtualServerNode(virtualServerNodeName, hash);
nodes.add(vsNode);
}
Collections.sort(nodes);
}
public synchronized void delPhyNode(String serverName) {
if (serverName == null || nodes.isEmpty()) {
return;
}
for (int i = 0; i < VIRTUAL_NUM; i++) {
VirtualServerNode node = nodes.get(i);
if (node.getServerNode().contains(serverName)) {
nodes.remove(node);
i--;
}
}
names.remove(serverName);
}
@Nullable
public synchronized VirtualServerNode getServerNode(String key) {
if (nodes.isEmpty()) {
return null;
}
MurmurHash3.HashValue hash = getHash(key);
for (VirtualServerNode node : nodes) {
if (VirtualServerNode.compareTo(node.getNodeHash(), hash) == 1) {
return node;
}
}
return nodes.get(0);
}
public static String getPhyName(VirtualServerNode virtualServerNode) {
return StringUtils.substringBeforeLast(virtualServerNode.getServerNode(), VIRTUAL_SPLIT);
}
public synchronized List<VirtualServerNode> getNodes() {
return nodes;
}
private MurmurHash3.HashValue getHash(String key) {
return MurmurHash3.murmurhash3_x64_128(key, seed);
}
}
|
这里需要额外说明Hash的算法采用,MurmurHash3的具体算法。这种算法相对于其他hash算法,更均匀且效率上更高。想要具体了解,可以参考w维基百科的说明。
Java计算出的Murmurhash3是两个64bit的long数值,这里通过BigInteger来进行相加计算,并做两两比较:
1
2
3
4
5
| public static int compareTo(MurmurHash3.HashValue v1, MurmurHash3.HashValue v2) {
BigInteger one = BigInteger.valueOf(v1.val1).add(BigInteger.valueOf(v1.val2));
BigInteger another = BigInteger.valueOf(v2.val1).add(BigInteger.valueOf(v2.val2));
return one.compareTo(another);
}
|
总结
OK,结束